常让我夜不眠的事物之一是 故障破解数据中心网络 通常多队参赛 每一队对网络、用户接口 和它支持应用有不同透视从历史角度讲,它人工检验网络复杂问题并使用自定义脚本编程、电子表格和CLI等解答解决故障和修复
并扩展成多云现代数据中心布局 大小部署正在成千上千件设备产生操作复杂性 管理这些装置的成本成倍增长 使用多工具方法解决故障需要更长时间多工具产生互不相容用户经验,导致大量时间人工处理全球网络故障排除和跟踪关键网络事件通常需要时间对错误行为设备或多设备数据采集分析可能导致故障快速变得昂贵
传统数据中心网络管理工具与方法假设速度与量变化远低于云生成值,无法满足云本地应用和数字商务需求
Cisconexs机板设计自动化监控分析网络基础实施创新架构方法以提供自动化和可见度规模Nexus平台透视简化客户操作程序 现代无国籍微服务架构 可横向缩放 使用开源基础设施代码透视提供动态相关关系、撞击分析、主动报警、故障预测和修复,同时提供操作数据可视化帮助整合所需操作工具数并减少应用故障时间、平均识别时间、平均解决时间和运营成本
驱动自动化和大规模可见性
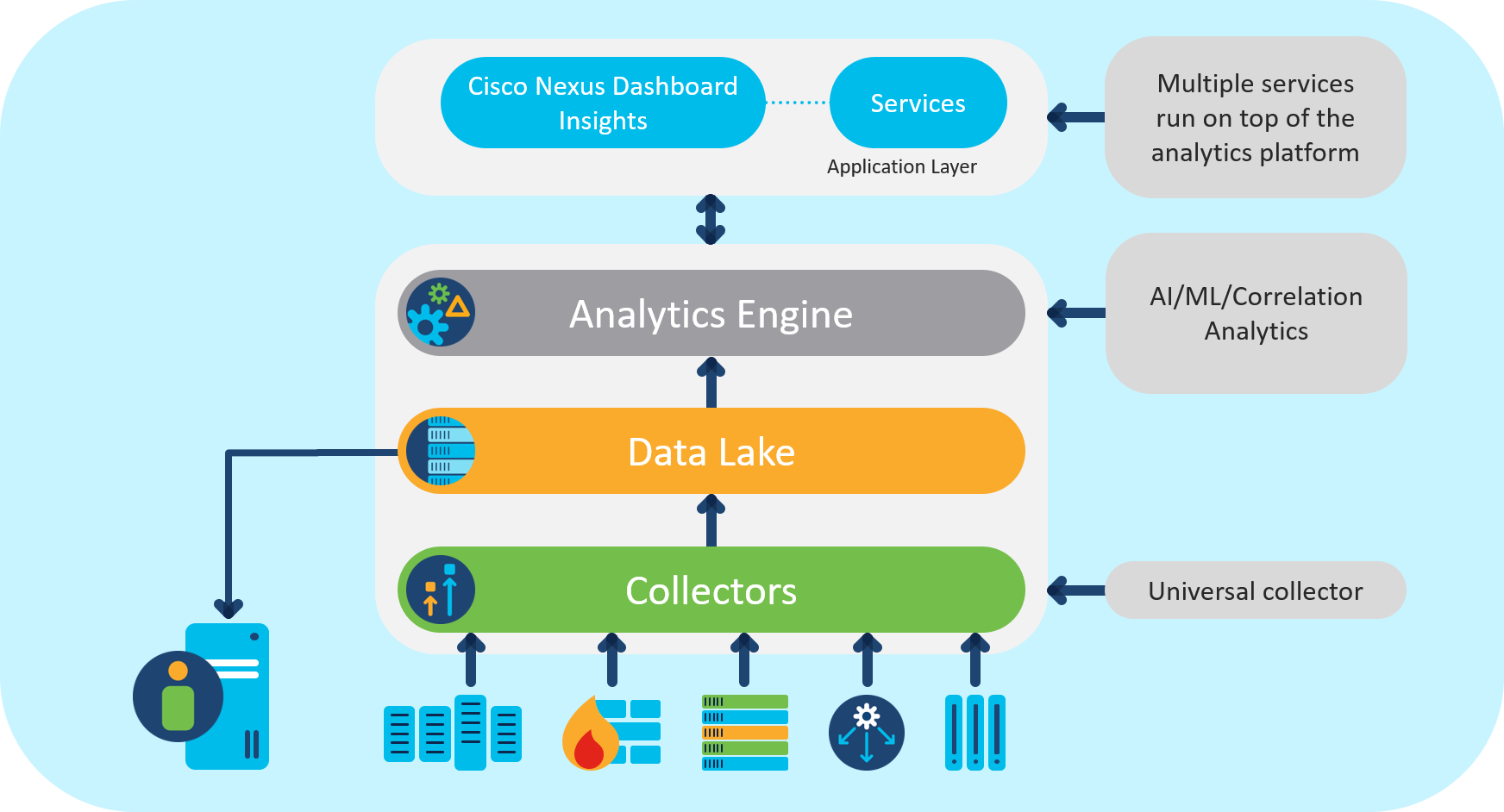
Nexus设计板透视架构关键构件
采集器NexusDashboard Insights综合通用遥测采集器收集器支持多输入插件收集从路由器、开关、防火墙和负载平衡器等网络基础设施设备流出软件和硬件遥测数据
数据湖透视管道支持JSON或GPB编码数据,数据转换并存储到数据湖中进一步处理遗留设备不支持流式遥测数据使用RESTAPI或SSH检索后放入管道变换
分析引擎 :分析引擎管道使用非服务器计算模型处理数据浓缩、异常检测、数据汇总和资源评分等任务,将任务划分为模块化任务并配有相关任务规范任务独立处理,结果保存在分布式数据湖
架构深度可见性和业务简单性
今天,我们正在利用最优类AI/ML技术实现数项任务自动化,这些任务正人工处理CLI或自定义ython脚本这使得强预测异常检测案例产生基于时间序列网络数据分析的警示,为主动预测能力铺路
透视从跨织物流出软件和硬件遥测使用AI/ML技术为不同关键性能指标创建网络基准基准持续更新以反映动态网络行为异常警示生成时网络状态跨过基准界定阈值带异常点可进一步触发用户指定动作,如生成邮件通知或自修
深入观察所基于的原则是,除识别网络问题外,还非常需要使复杂IT操作监控简单化。开始自动化行程 开始采取更多步骤 识别问题/问题和由此产生的修复步骤
解决对现代网络的架构需求
- 硬件软件遥测深入分析硬件和软件遥测知识:提高数据完整性和精度帮助实时监控故障排除
- 防未来支持未来防患于未然支持基础设施设备使用全行业支持开放标准中具体规定的能力
- 带头AIOS:利用AIOS能力建立闭合连续回路自动化修复监控源码问题和规模支持需求通过DevOps工具链实现开发敏捷化并实现实时自动模式发现
允许我们自动化管理遗留数据密集过程,同时接受云驱动新数据框架

留意下一组博客探索NexusDashboard能力并使用案例
- 单视图:用单点登录和角色访问控制运行多点分布环境,跨多点CiscoNexusDashboard单点控制
- 微爆检测:深入网络微爆流探索并定位隐微爆点 定位拥塞热点 保护应用性能
- 异常分析i/FCS错误解析问题对比时间同步多参数数据以加深对问题和行为的理解
资源类




连接CISCO