作者:Siva Sivakumar-数据中心解决方案高级主管
概述提供Hadeop和AI客户额外选项运行Hadeop或Kubernetes农场使用Apachespark
阿帕契spark3.0新发布程序使客户能够聚集数以百计的NVIDIAGPU资源跨数以百计节点运行单分布深度学习任务TensorFlow等不同的AI框架在spark内工作,为Hadoop内更多NVIDIAGPU加速工作铺路
分布式深入学习cisco数据智能平台NVIDIAGPUs
数月前写入数据科学家首次通过从不同节点集合NVIDIAGPU资源,在数据湖内单工工作(由YARN管理)ApacheSubmarine
带今日公告NVIDIA为Apachespark3.0提供GPU支持,数据科学家现在可以选择加速Apachespark原生式这种分布式深学习工作量
阿帕契社区发布预览spark3.0帮助spark本地访问GPUs(通过YARN或Kubernetes),为各种更新框架和方法开通通道,分析Hadoop内部数据
Apachespark自然演化将迎合新计算形式,如NividiaGPUs加速计算,并将为客户提供更多选项分析数据
- 不同形式计算spark不再局限于CPU工作现在它可用分布式方式使用各种计算形式,例如ETL(Extrap、变换加载)和AI作业的CPUs和GPUs
- 分布式GPU集合spark3.0新发布程序使客户能聚集数以百计节点数数以百计的NVIDIAGPU资源运行单分布式GPU加速工作
- 支持多调度器Spark3.0可同时工作YARN-YARN容器或Docker容器原生Hadoop调度器-或Docker容器Kubernetes-为Docker容器-向客户提供更多选择解决不同使用案例
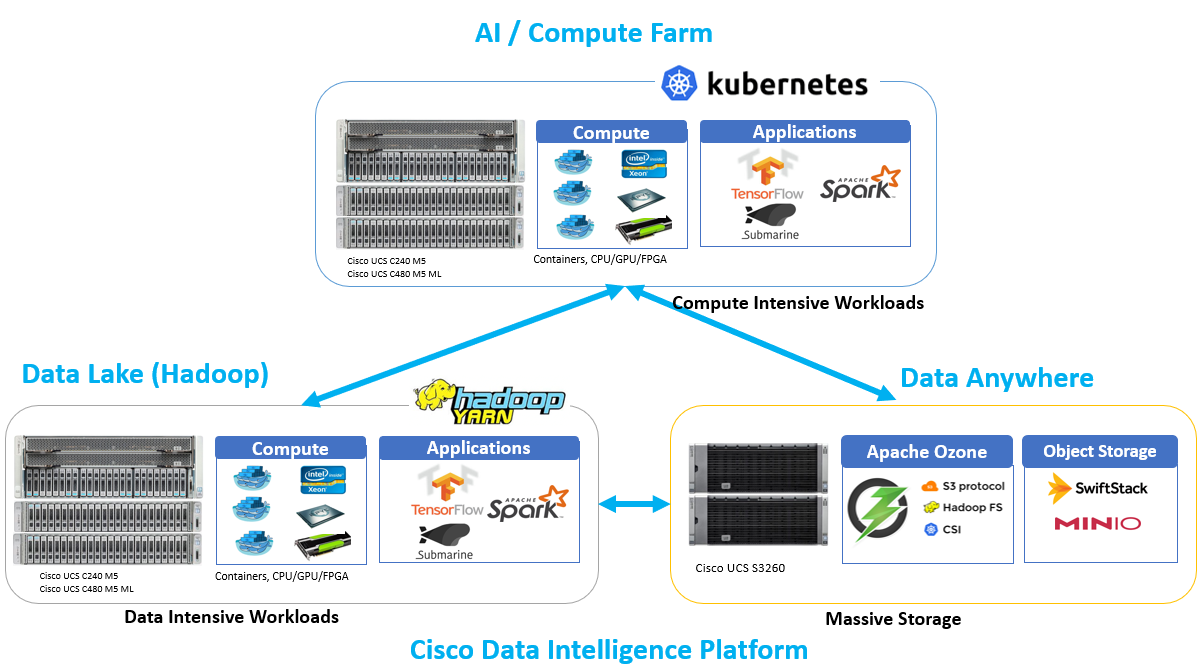
使用Cisco数据智能平台启动新工作
Cisco数据智能平台强健平台提供架构基础 帮助Hadeop社区这些令人振奋的新开发这些特征将为数据科学家和数据工程师提供新工作量和使用案例,包括:
- 深入学习工作直接与YARN或Kubernetes
- 深入学习工作框架如TensorFlow、PyToch等YARN或Kubernetes通过ApacheSubmarine
雷竞技真的能提现吗Cisco和NVIDIA协作交付
Cisco和NVIDIA联合提供GPU加速数据中心来增强人工智能并加速分析实践,使你能够加速洞见和结果,Turbo充电数据库并面向未来创新
Cisco统一计算系统支持各种NVIDIAGPUs提供最高数据分析工作量所需的计算能力
Cisco数据分析空间的悠久历史,加之NVIDIA在驱动GPU加速工作的领导位置,使客户很容易利用这些新Apachespark能力
阿帕契spark3.0
Cisco和NVIDIA联手演示数据科学家如何利用Apachespark3.0启动大规模深学习任务运行TensorFlow应用下图展示YARN池和调度GPUs如何跨节点使用spark3.0分布作业说明数据科学家如何监测工作进度,IT可监测资源
内文摘要
Cisco数据智能平台NVIDIA GPUs提供Hadoop和AI客户额外选项运行Hadeop或Kubernetes农场的AI工作量
深入了解思科数据解析法www.cisco.com/go/bigdata






owoww