想象一下你被请求创建架构 来应用解析 巨量数据像摄像头生成视频流量度敏感度数据 并不想寄出异常分析同时 数据集中预期成本 可能使您的使用案例商业价值评估失效可应用机器学习或人工智能-但前提是你可用计算资源使机器学习有效
这正是我最近由我的同事Michael Wielpuetz帮助处理的挑战
在典型边缘假设中改变或缩放可用计算资源并不总是容易或甚至可能的ML或AI辅助软件栈由库、框架和训练有素分析模型组成相对于网络边缘可用资源而言,框架和模型往往规模大。此外,这种搭建往往需要多CPU环境或甚至GPU驱动环境运维
提供思想食用新思想并证明可能性 Michael Wielpuetz和我开始自由时间 以最小化资源需求探索视频流人脸 以及这些脸是否蒙上保护罩
Docker基础图像设计出两个堆叠神经网络:第一个神经网络检测视频流中所有面孔,第二个神经网络检测面孔发现最小化容器并跨x86_64和ARM64架构使用,我们编译、交叉编译并最小化从千兆字节到兆字节大小所有构件的足迹允许使用最小AI框架之一,我们转换、量化并拆卸训练模型我们决定投入额外努力优化框架和库,因为当我们启动时,没有可即时安装包可供最新版组件使用
看标准Docker图像与基础图像对比

ARM64上图像的最后尺寸为184MB,仍然有进一步优化的潜力
神经网络嵌入允许动态配置的应用中,例如配置视频流使用,定义分辨率和采样率等环境设置对传输量和数据可用性定时有重大影响
系统测试量为5乘以720p解析数达5框架,Docker容器可用资源中只有一部分可用资源允许同时托管多个容器最优设置和所需吞吐量取决于使用案例需求多例用法完全正常 以每秒一格或更少
Docker容器内部结构如下:
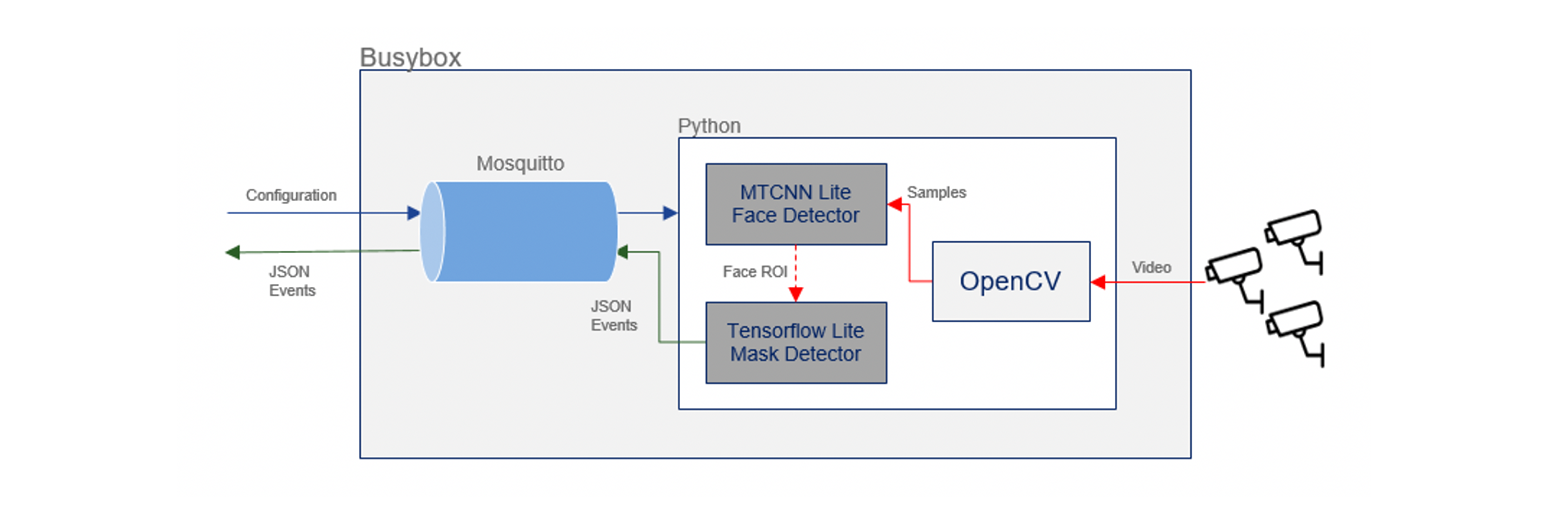
自Docker基础图像与可配置视频流合作后,很容易想出更多使用案例演练替换或再培训模型以覆盖基于视频流的其他场景,以便能够使用案例,如检测房间占用性、人数计数、威胁检测、物体检测等等
举个例子来说明行动搭建视频将显示:
- 上段动态匿名表情检测
- 第二段视觉表示分析结果,包括脸部位置、面部特征以及个人戴面罩概率
- 第三段原创视频流并可视化检测
- 第四段内输出搭建
第四段正是搭建为外部消费者提供的东西维护隐私程序不会发送视频或图像数据流出
仍有空间优化分析结果的精度首创搭建时,我们特意聚焦于证明表演ML和AI边缘的可能性和资源配置下降,而不是创建即用产品
计划制作小数基于视频的其他例子, 并转而聚焦机器遥测和如何使用高维数据方法计划继续发布不同的docker图像供不同使用案例帮助其他人启动ML和AI边缘




丹尼尔 迈克尔
解决方案听起来很有趣,你是否计划 实施DevNet沙盒环境
高山市https://developer.cisco.com/site/sandbox/)
或多或少,
我正在和DevNet谈听起来像一个好主意 提供更广泛访问它 测试目的
优秀信息保持
棒极了
感谢提供深入IoT技术期望看到你多发启发性文章
保持监听
真正有趣的是看到通过优化图像可实现的差分干得漂亮