![]()
后继大数据安全序列第一部分TRAC工具与BerkeleAMPLab大数据栈讨论TRAC的工作
加利福尼亚大学研究者伯克利AMPLab搭建开源伯克利数据分析栈
AMPLab从略微不同的角度看待大数据问题,新颖角度包括数个不同组件下层查看栈时,请见Mesos,这是一个资源管理工具集群计算假设你有一个集群运行 Hadoop地图稀释作业、MPI作业和多线程作业ess管理可用计算资源并高效分配各类工作传统Hadoop集群中,只有一份Map-Reduce作业在任何一个时间运行,该作业阻塞所有集群资源。而Mesos则坐在集群顶上管理所有类型计算资源Mesos类同ApacheYARN,这是另一个集群资源管理工具TRAC目前不使用Mesos

Source: https://amplab.cs.berkeley.edu/software/
你提到书栈小说,如何
最令我们感动的层是Spark,即栈地图-Reduce引擎。Spark后的创新思想是弹性分布数据集概念For the purpose of fault tolerance, Hadoop Map-Reduce uses redundancy in the sense that after every stage of a Map-Reduce job, multiple copies of the intermediate results are written to disk on different nodes, so that in the case of losing a process or a node, the part of the job that was lost may be restarted from the last finished stage. This writing to and reading from disk at each stage of a job significantly slows down the whole process. In Spark, on the other hand, the concept of redundancy for fault tolerance is replaced by the concept of RDD. For the purpose of fault tolerance, for each RDD, which is, in principle, a slice of a data set, Spark keeps the lineage of the RDD. So for each RDD, Spark remembers how it was built and the set of transformations that happened on the data to make that RDD.万一特殊RDD丢失(使用丢失RDD线程)Spark可从零重建RDD
spark执行 Map-Reduce作业执行规划方式也是新奇的。如果作业阶段可合并到一个阶段,spark自动规划执行作业Spark地图-Reduce中这种优化比hadoop地图-Reduce快得多
Spark特征丰富,最有趣的能力之一是模拟计算。你可以以分布式方式加载全RDD或它部件内存并随后使用缓存数据计算并因此节省大量时间使用缓存数据代替读盘数据可能导致二阶级快速计算
鲨鱼是另一个创新BDAS元素。 鲨鱼为spark提供SQLAPI,它等同Hive Hadoop地图-Reduce,但更优化并使用模拟选项。 Shaps比Hive等工具的优势来自局部DAG执行、地图编程和模拟能力等优化应用
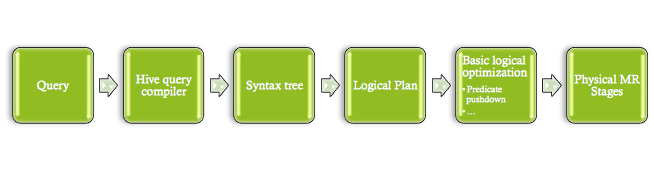
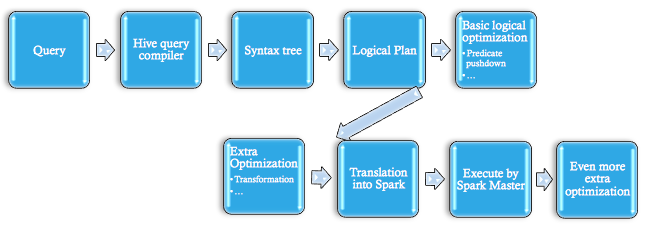
TRAC为何决定使用spark
大量数据使用需要能够理解数据并使用它,对它进行批量归纳,从数据中提取预测信号。 Spark提供各种大设施组合,以简单高效方式执行所有类型数据。spark很容易使用,Scala、Java和Python有APS使用sparkscalaAPI为一组文本文件写字计数码同下行一样简单:
valC=sc.textFile
ava Hadoop地图-Redce中类似功能从字面上讲需要100多行代码。看地图-Reduce编程的其他选项,我们发现spark是最强工具之一,表现、灵活性、易用性、易用性、与其他语言融合易用性,当然还有模拟能力Pig最受欢迎地图语言之一Hadeop使用,
更灵活资源管理集群也是一个强大的spark特征运行传统Hadoop地图生成作业时(重置HDFS),该作业基本占用全集群并使用所有集群资源,因此您有单作业队列Spark系统可具体说明每项作业需要多少资源(CPU和内存),结果多作业可同时运行集群
Spark模拟能力也大有裨益下行地图工具不提供此选项特别对机器学习算法等迭代过程而言,这种模拟能力变得非常实用性内存量较大后,宜用内存计算数据而非硬盘计算数据内模工具处理大数据需求继续增长,迄今为止Spark正在领先包
Spark还提供交互式Scala界面,这是一个命令行环境类似于Scala外壳。Spark连同模拟能力使Spark实时大数据分析超工具启动Spark地图-RedceScala基础地图语言,如Spark、Scoobi、Scrunch和ScaldingSpark的相对功能使用 包括模拟特征
顶端是BlinkDB
BlinkDB是一个SQL查询引擎,以约数秒或分秒处理大规模数据集查询BlinkDB通过采样实现这一辉煌目标是理解数据上定期运行的查询类型并创建数个分层样本记录查询和不同置信区间。用户可指定置信度(例如95%)和/或查询最大时间(例如2秒),然后BlinkDB选择右样并运行查询。这些样本用不同的置信区间和时间框架处理不同的查询,并脱机
BlinkDB首次发布约3个月前发布。工具还很年轻,缺少BlinkDB论文描述的一些特征对BlinkDB即将发布,我们感到兴奋,我们正在调查当前发布,以评估我们如何从BlinkDB能力中受益

Source: http://ampcamp.berkeley.edu/wp-content/uploads/2013/08/BlinkDB-sameer-agarwal-AMPCamp-3.pptx
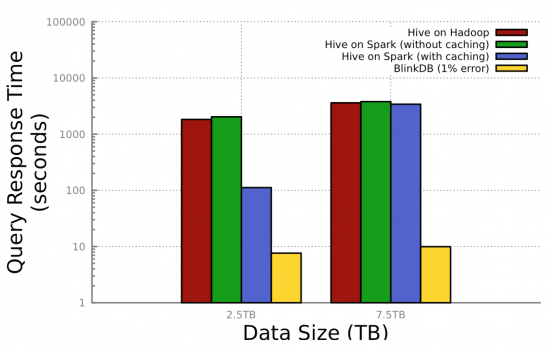
对TRAC而言,BlinkDB使用案例中有哪些
威胁分析有用 数据集大,我们需要理解数据 而不花太多时间快速解答问题像:哪些领域不同?人多多?异常点是什么
TRAC构建混合栈包括AMPLab组件解决TRAC使用案例吗?
完全正确,我们已经调查 数据解析栈每一层 各种工具此时点,我们已经巩固堆栈选择,例如我前面提到,spark是我们对地图-Redce部分需求的选择
测试分析板块编译自定义栈, 你确信这是实现思科当前和今后安全分析目标 最佳解决方案吗?
大数据区非常动态 每隔一周我们都会听到新工具永远不能完全相信一种解决方案,因为明天可能发布游戏变换工具。 此外,大数据问题并不存在“TH解决方案 ” 概念,而不同的解决方案应该在适当上下文和特定使用案例中加以考虑。置新科技和新研究为顶峰 并持续精炼书栈我们投入了大量资源 堆栈的每一层, 如果我们快照今天的情况......我们完全确信我们的解决之道
大数据安全对话到此结束 mahdi额外AMPLabStack评论s.co/6011dHBT.补上昨天的TRAC工具博客和Michael Howe和Pretham Raghunanda谈起他们的激动人心时,不要错过明天的QA图解析工作.
 Mahdi Namazifar2013年1月加入TRAC前,他是Opera解决方案科学家,研究各种数据解析和机器学习问题,如金融和保健等行业2008年获硕士学位,2011年获威斯康星大学运营研究博士mahdi在IBMTJ实习华生研究实验室和圣地亚哥超级计算机中心.马赫迪的研究兴趣包括机器学习、数学优化、并行计算和大数据
Mahdi Namazifar2013年1月加入TRAC前,他是Opera解决方案科学家,研究各种数据解析和机器学习问题,如金融和保健等行业2008年获硕士学位,2011年获威斯康星大学运营研究博士mahdi在IBMTJ实习华生研究实验室和圣地亚哥超级计算机中心.马赫迪的研究兴趣包括机器学习、数学优化、并行计算和大数据






干得漂亮马赫迪
大数据区实现数据安全大有进步
需要用微镜检查安全性时, 精度应绝对谨慎化, 并实现BlinkDB