文章由创用卡雷尔巴特斯并Martin Rehak
网络流量在过去几年中稳步增长同时云数据中心提供关键服务不仅增加流量,而且增加复杂事务
高量网络流量允许攻击者有效隐藏后台此外,攻击者可以通过制造大规模非恶意网络活动连发转移或欺骗内部检测系统模型这类活动通常引起统计检测方法的注意,并进一步报告异常事件,而重要但小得多的恶意活动则不被承认。反之,我们需要部署更精密检测模型和算法 检测这种小型隐藏攻击交易日志量的增加也带来了计算算法问题,因为这些算法很容易变得难以计算全流量日志
采样减少输入网络数据量,由检测系统进一步分析,允许任意复杂性系统运行网络链路,而不论其大小然而,样本数据使用CTA有问题,因为它对效果有负面影响。CTA算法基于统计流量分析并自适应模式识别,对流量特征的曲解通过破解对流量特征的假设可大大提高这些底层方法的误差率采样方法信息丢失也对法证调查产生消极影响。
先看一例非采样流量一维关于这些例子,我们正在集中关注源IP地址流数图1显示20源IP地址的相应特征分布特征值取原创输入数据计算,信息不损耗,分布不偏差这是理想案例不幸的是,如前所述,更精密算法计算需求需要减少输入数据才能完成给定时间段处理所以我们需要应用采样并获取采样结果 尽可能接近此分布

图120源IP地址流数计算自原创数据分布不偏,然而检测算法计算需求高
下三个例子中,我们将缩小输入数据大小管理检测成本第一,我们将试随机采样(包或流基采样),该采样由于简单实现和低计算需求而广泛使用采样先随机选择包或流并计算特征并实现检测表示采样早期随机采样.早期随机采样对多数检测或分类方法产生消极影响图2举例说明了这种撞击与原分布图对比(图1),早期随机采样不仅影响分布形状,还消除大部分稀有特征值可见此采样完全消除8源IP地址所有流2IP13IP15IP20码和剩余特征值不精确最重要的是,消除值通常是应发现并报告的潜在恶意值
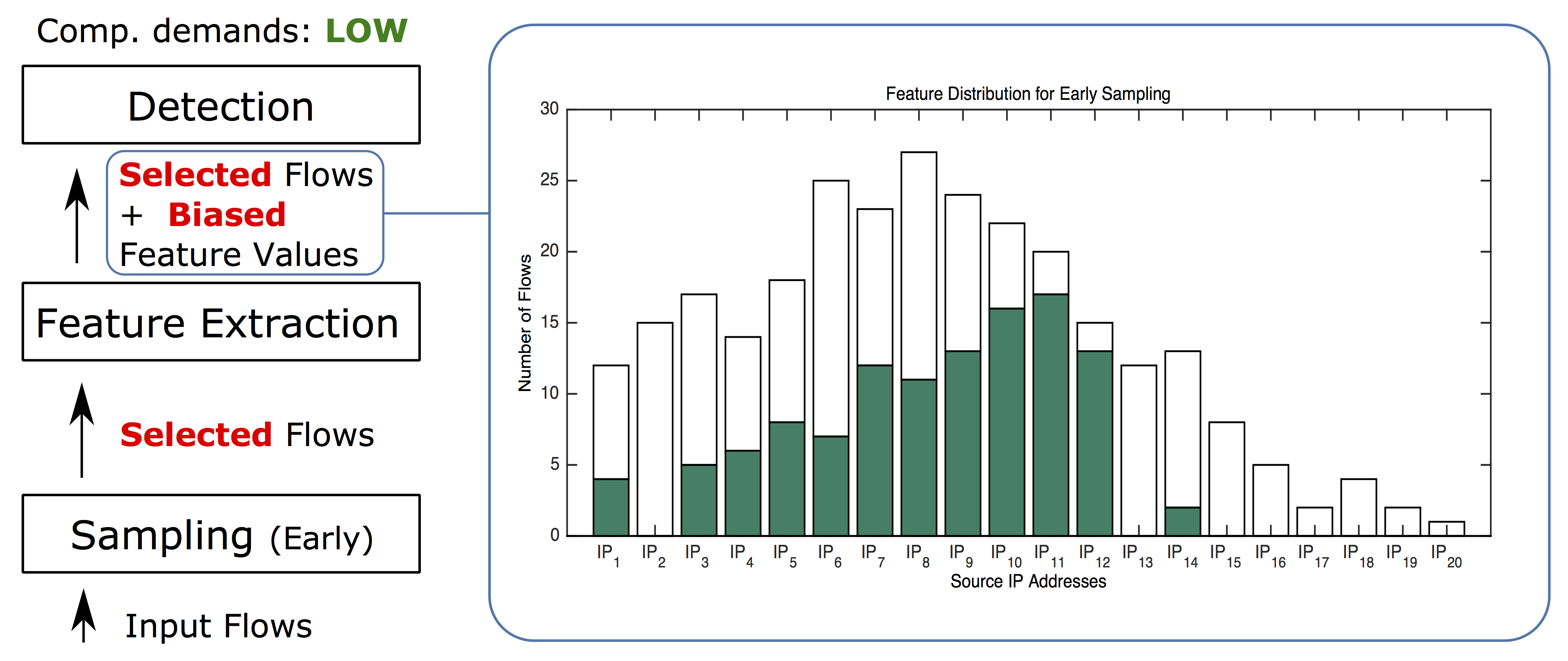
图2效果学早点随机特征分布采样由于流先随机选择,然后计算特征值,早期随机采样负移特征分布8源IP地址流完全消除(纯白条),其余值高度不精确
下例中,我们用某些计算功率从原创(非采样)数据提取特征值保证特征价值不偏差特征值计算后,随机采样会减少检测算法输入流数我们称它为方法晚随机采样.图3显示结果对特征分布的影响早期采样引入比亚斯值大幅下降,快速提高统计方法检测性能八源IP地址流仍然缺失,因为没有一个地址通过随机采样选择
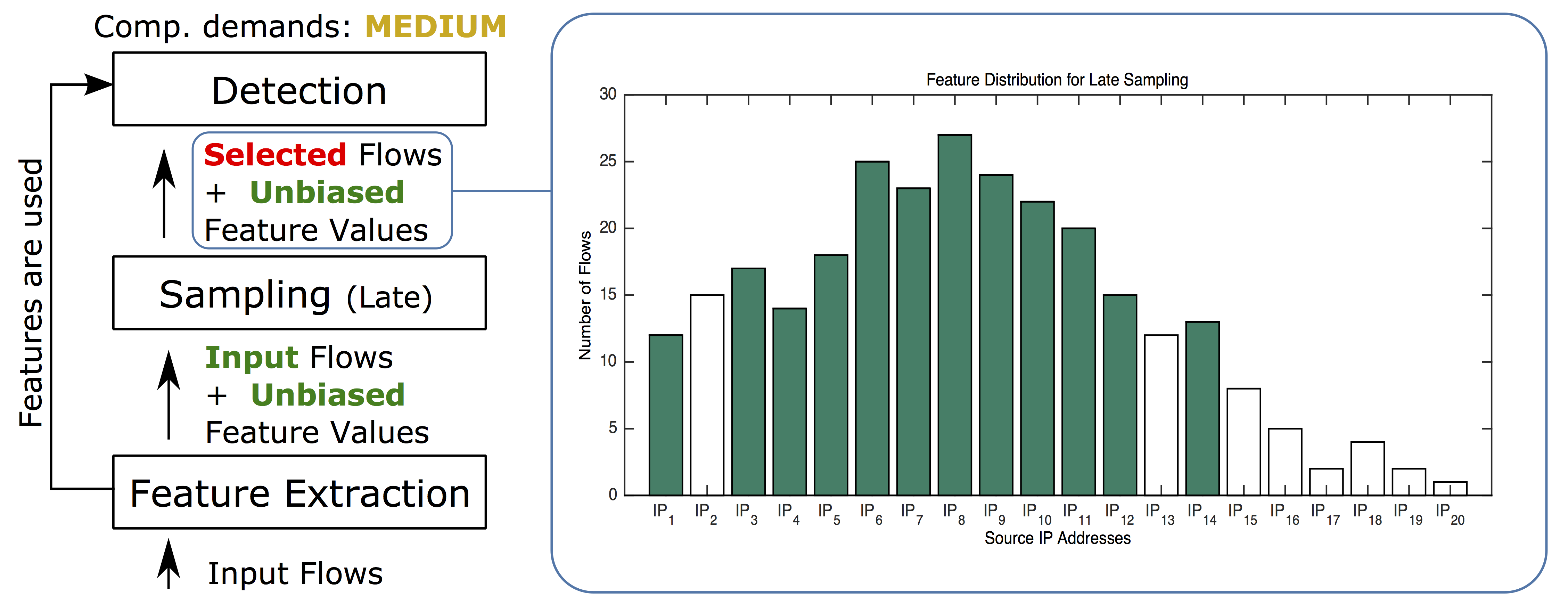
图3晚点随机采样保留采样所选流的非偏差特征值源IP地址少流仍然消除
上例举晚适应采样.延时采样提高率,根据流特征值修改采样率,以最大限度地提高生存样本的可变性延迟自适应采样根据特征值大小选择流量,以便淡出大度、可见度和易检测事件,并更频繁地选择稀有事件(常与隐藏恶意活动相关)。适应式和延迟采样组合最小化特征分布偏差对随后检测方法至关重要,图4显示延迟采样允许自适应采样强调数据可变性保护,因为比例因特征提取而保持

图4自适应性采样增加选入采样集流数(和源IP地址数)的变异性,而同时晚点采样保留选流的非偏特征值组合式晚适应引出最大保留特征值
如何应用CTA方法实际-我们再走一步云基服务CTA本能上对计算需求变化比较耐受,活动暴不难管理正因如此,我们比论文描述的方法先行一步IFS:智能流采样网络安全-自适应方法.我们搭建了廉价(计算式)统计检测器,可应用到全局,非采样流量,并充分估计出任何流水的恶意性由这组检测器选择相对小子流详细威胁检测分类类似漏斗法使我们能够大规模交付高精度采样系统已有效内部化
强信采样不利于安全能力管理问题所在的预测解析法 即实现之道




连接CISCO