从新闻报道、文章、博客和水冷故事量中可以明显看出人工智能和机器学习正以基本方式改变社会-行业正在快速进化以跟上爆炸性增长
可惜过去高性能计算网络无法满足AI/ML需求作为一个行业,我们必须进化思维并构建可扩展和可持续的AI/ML网络
今日产业分治 AI/ML网络环绕四大独有架构构建:Infiniband、Ethernet、遥测辅助Ethernet和完全定时布局
每种技术都有利弊, 各种层次1网络算法对权衡有不同的取舍正因如此,我们看到业界同时向多方向发展,以适应当前快速大规模搭建
现实正是Cisco硅一号价值建议的核心
客户可部署思科硅一号为AI/ML网络提供动力并配置网络使用标准Ethernet、遥测辅助Ethernet或完全定时布局随工作量演化,他们可以继续进化思科Silicon One编程架构
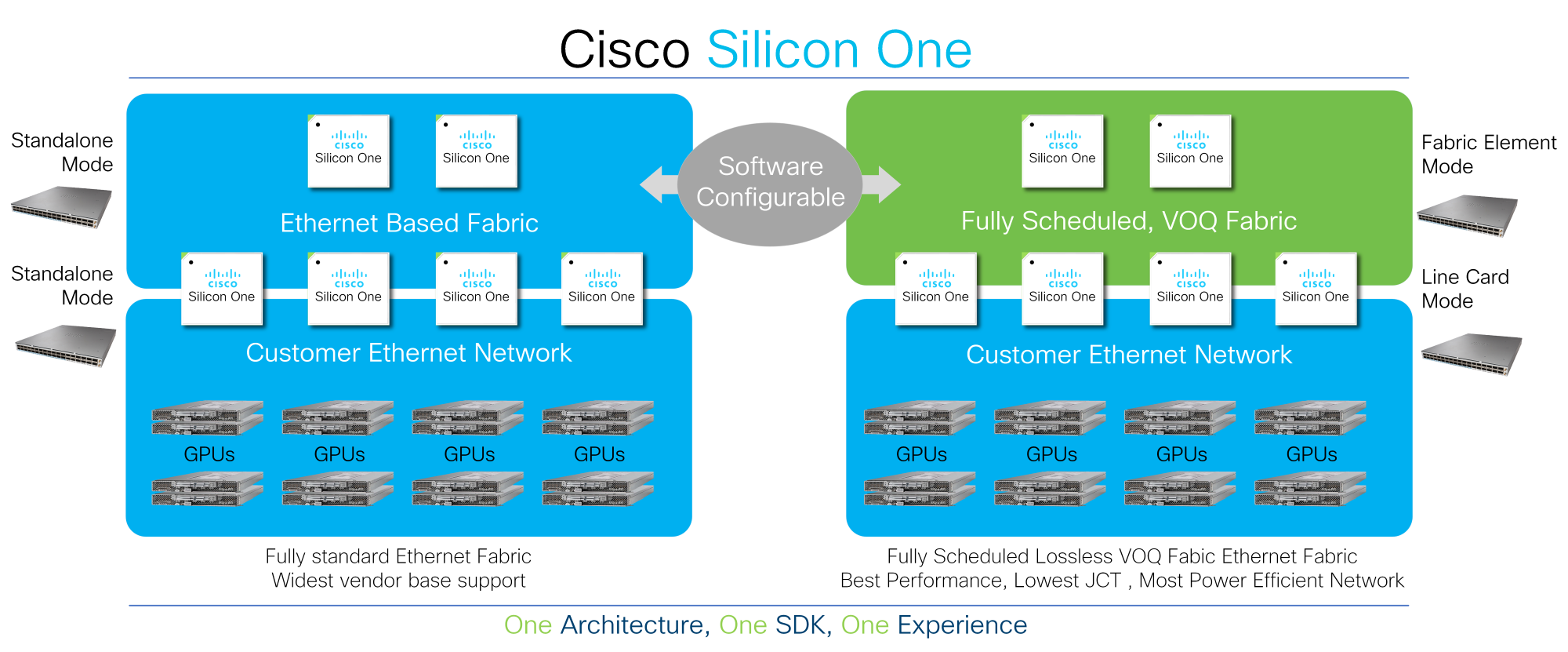
市场上所有其他硅架构锁定组织窄部署模式,迫使客户提前购买时间决策并限制其进化灵活性Cisco Silicon One向客户提供将网络编程成各种运维模式的灵活性,并提供每种模式中最流畅特征Cisco硅一号可启动多架构,客户可关注数据现实并按自身标准做出数据驱动决策

帮助理解每种技术的相对优异性 理解AI/ML基础知识很重要AI/ML像多词一样过分简单化许多独特技术、使用案例、交通模式和需求简化讨论方式,我们将集中关注两个方面:培训集群和推理集群
培训集群设计时使用已知数据创建模型集群类火车模型学这是一种异常复杂迭代算法,遍历数众多GPUs并可运行数月生成新模型
推理集群并用训练模型分析未知数据并推算答案简言之,这些集群推理未知数据与已训练模型推理集群计算模型小得多和OpenAI交互聊天GPT或谷歌巴德,我们正在交互推理模型模型长段数以十亿计或甚至数万亿计参数进行非常重要培训后产生这些模型。
聚焦训练集群分析以太网性能、遥测辅助以太网和完全定时布局我分享更多细节 关于这个题目在我的OCP全球峰会,2022年10月.
AI/ML培训网络自成一体大规模后端网络构建,交通模式与传统前端网络大不相同。后端网络用于专用端对端传输存储网过去曾用于存储互连,然而,随着远程直接存取和RDMA对聚合以太网的出现,很大一部分存储网现在建在泛以太网上。
现时这些后端网络正用于HPC和大规模AI/ML培训集群正如我们在存储场所见,我们正在目睹从遗留协议迁移
AI/ML培训集群与传统前端网络相比有独特的交通模式GPUs完全饱和高带宽链路,通过数据传输向同行发送计算结果,即全对全集体传输结束时,屏障操作确保所有GPU都更新创建网络同步事件令GPU闲置,等待网络最慢完成路径工作完成时间测量网络性能以确保所有路径运行良好

流量非阻塞并产生同步高带宽长流前端网络数据模式大相径庭,前端网络主要由多非同步小带和短寿命流组成,并有较大异步长存流储存差异和JCT平均网络性能至关重要
分析网络性能时,我们创建了小训练集群模型256GPUs、8顶机架开关和4脊柱开关并发数并发并发网络和网络加速量
研究结果戏剧化
大型AI/ML培训集群与HPC不同,HPC是为单项作业设计,而大型AI/ML培训集群设计是为了运行多项同时作业,类似于网络规模数据中心今天发生的事情。工作数增加后,网络用负载平衡法效果更加明显16个作业遍历256GPUs,完全定时织物产生1.9x快速JCT

以另一种方式研究数据,如果我们监控优先流控量从网络发送到GPU,我们看到5%GPU慢化其余95%GPU完全定时布局提供完全非阻塞性能,网络永不中断GPU

表示对同一网络,您可以全排布为相同大小网络连接二倍GPU遥测辅助以太网的目标是通过信号拥塞改善标准以太网性能并改进负载平衡决策
如我前文所述,各种技术的相对优劣因客户而异,并可能不会随时间变化而稳定不变。以太网或遥测辅助以太网虽然性能比完全排定布料低,但极值技术,并将广泛应用到AI/ML网络中
客户为何选择一种技术比另一种技术
客户想享受以太网高额投资、开放标准及优先成本带动态应部署以太网加入AI/ML网络通过投资遥测和最小化网络负载可以提高性能,
客户想享受全非阻塞性能虚拟输出队列全套定时喷射重排序布局,从而实现1.9x更好的工作完成时间,应全程部署AI/ML网络布局全排程布料对客户也大有帮助,客户想通过删除网络元素节省成本和电量,但仍能实现与以太网相同的性能,2x为同网络计算更多数
Cisco Silicon One具有独特定位,为这两个客户中的任何一个提供求解方法并发架构和行业引导性能

学习更多 :
读取 :AI/ML白皮书
访问量 :思科硅一号






路Cisco,我是一个学生 并学习你公司看到你2021年所经历的挑战 并保持强健和创新是鼓舞人心和勇敢祝愿你万事如意
谢谢大卫这是一个伟大的时间为思科工作自1997年以来我一直在这里,我可以轻易地说,这是思科工程师最令人兴奋的时刻。最优创新